
Virtual Training

Detecting pedestrians in images is a key functionality to avoid vehicle-to-pedestrian collisions. The most promising detectors rely on appearance-based pedestrian classifiers trained with labelled samples. This paper addresses the following question: can a pedestrian appearance model learnt in virtual scenarios work successfully for pedestrian detection in real images? Our experiments suggest a positive answer, which is a new and relevant conclusion for research in pedestrian detection. More specifically, we record training sequences in virtual scenarios and then appearance-based pedestrian classifiers are learnt using HOG and linear SVM. We test such classifiers in a publicly available dataset provided by Daimler AG for pedestrian detection benchmarking. This dataset contains real world images acquired from a moving car. The obtained result is compared with the one given by a classifier learnt using samples coming from real images. The comparison reveals that, although virtual samples were not specially selected, both virtual and real based training give rise to classifiers of similar performance.
Supervised Domain Adaptation
 Image based human detection is of paramount interest for different applications. The most promising human detectors rely on discriminatively learnt classifiers, i.e., trained with labelled samples. However, labelling is a manual intensive task, especially in cases like human detection where it is necessary to provide at least bounding boxes framing the humans for training. To overcome such problem, in Marin et al. we have proposed the use of a virtual world where the labels of the different objects are obtained automatically. This means that the human models (classifiers) are learnt using the appearance of realistic computer graphics. Later, these models are used for human detection in images of the real world. The results of this technique are surprisingly good. However, these are not always as good as the classical approach of training and testing with data coming from the same camera and the same type of scenario. Accordingly, in Vazquez et al. we cast the problem as one of supervised domain adaptation. In doing so, we assume that a small amount of manually labelled samples from real-world images is required. To collect these labelled samples we use an active learning technique. Thus, ultimately our human model is learnt by the combination of virtual- and real-world labelled samples which, to the best of our knowledge, was not done before. Here, we term such combined space cool world. In this extended abstract we summarize our proposal, and include quantitative results from Vazquez et al. showing its validity.
Image based human detection is of paramount interest for different applications. The most promising human detectors rely on discriminatively learnt classifiers, i.e., trained with labelled samples. However, labelling is a manual intensive task, especially in cases like human detection where it is necessary to provide at least bounding boxes framing the humans for training. To overcome such problem, in Marin et al. we have proposed the use of a virtual world where the labels of the different objects are obtained automatically. This means that the human models (classifiers) are learnt using the appearance of realistic computer graphics. Later, these models are used for human detection in images of the real world. The results of this technique are surprisingly good. However, these are not always as good as the classical approach of training and testing with data coming from the same camera and the same type of scenario. Accordingly, in Vazquez et al. we cast the problem as one of supervised domain adaptation. In doing so, we assume that a small amount of manually labelled samples from real-world images is required. To collect these labelled samples we use an active learning technique. Thus, ultimately our human model is learnt by the combination of virtual- and real-world labelled samples which, to the best of our knowledge, was not done before. Here, we term such combined space cool world. In this extended abstract we summarize our proposal, and include quantitative results from Vazquez et al. showing its validity.
Unsupervised Domain Adaptation
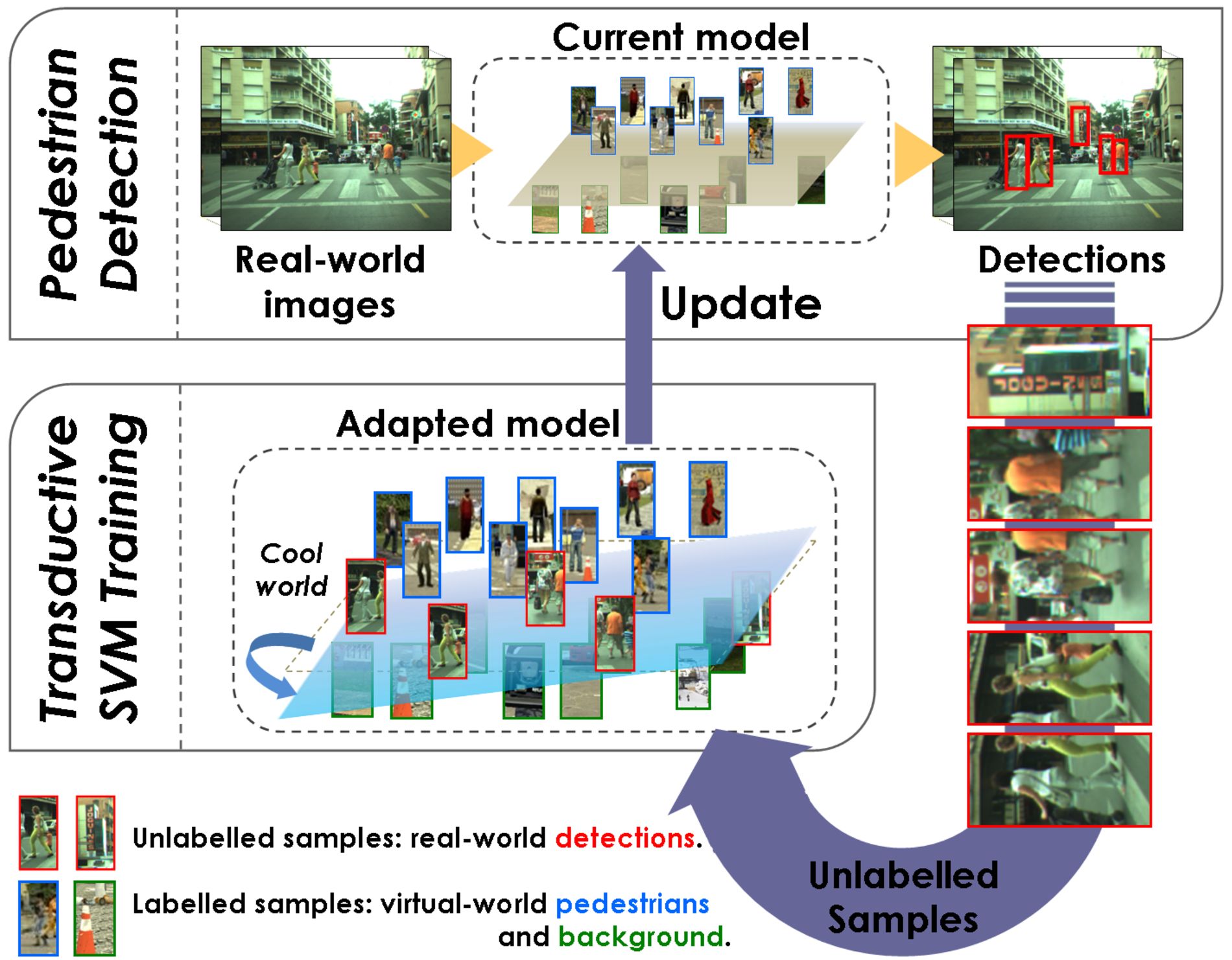 Vision-based object detectors are crucial for different applications. They rely on learnt object models. Ideally, we would like to deploy our vision system in the scenario where it must operate, and lead it to self-learn how to distinguish the objects of interest, i.e., without human intervention. However, the learning of each object model requires labelled samples collected through a tiresome manual process. For instance, we are interested in exploring the self-training of a pedestrian detector for driver assistance systems. Our first approach to avoid manual labelling consisted in the use of samples coming from realistic computer graphics, so that their labels are automatically available. This would make possible the desired self-training of our pedestrian detector. Between virtual and real worlds it may be a dataset shift. In order to overcome it, we propose the use of unsupervised domain adaptation techniques that avoid human intervention during the adaptation process. In particular, this paper explores the use of the transductive SVM (T-SVM) learning algorithm in order to adapt virtual and real worlds for pedestrian detection.
Vision-based object detectors are crucial for different applications. They rely on learnt object models. Ideally, we would like to deploy our vision system in the scenario where it must operate, and lead it to self-learn how to distinguish the objects of interest, i.e., without human intervention. However, the learning of each object model requires labelled samples collected through a tiresome manual process. For instance, we are interested in exploring the self-training of a pedestrian detector for driver assistance systems. Our first approach to avoid manual labelling consisted in the use of samples coming from realistic computer graphics, so that their labels are automatically available. This would make possible the desired self-training of our pedestrian detector. Between virtual and real worlds it may be a dataset shift. In order to overcome it, we propose the use of unsupervised domain adaptation techniques that avoid human intervention during the adaptation process. In particular, this paper explores the use of the transductive SVM (T-SVM) learning algorithm in order to adapt virtual and real worlds for pedestrian detection.